
Wstęp
Czołem w piątek.
Od ponad roku jedną z moich zawodowych aktywności jest tworzenie rozwiązań korzystających z LLMów. Od początku używałem natywnej biblioteki open AI li ollama przy używaniu lokalnych modeli. Próbowałem różnych frameworków, a raczej próbowałem się z nimi zaprzyjaźnić ale wyszło to słabo. Albo nie widziałem żadnych plusów albo był na tyle skomplikowany i magiczny, że nie miałem czasu do tego porządnie przysiąść.
Jednym z takich, do którego planuję usiąść na poważnie jest Semantic Kernel od Microsoftu ale tam się dzieją magiczne rzeczy pod spodem, a ja strasznie lubię mieć poczucie kontroli nad tym, co się dzieje w aplikacji.
Jakiś czas temu trafiłem na pydantic ai i przyznam, że to miłość od pierwszego wejrzenia. Na razie używam praktycznie podstaw, ale i te bardzo ułatwiają pracę, pozostawiają do kontroli to co istotne, a ułatwiają rzeczy bardziej żmudne.
Jeśli pracujesz w Pythonie, prawdopodobnie znasz Pydantic za walidację danych. Pydantic AI wykorzystuje tę samą filozofię do interakcji z LLM. Zamiast prosić model o wygenerowanie JSON-a i modlić się, żeby trzymał się schematu, definiujemy po prostu klasę Pydantic, a framework zajmuje się resztą.
To genialne w swojej prostocie. Gwarantuje, że dane wyjściowe z modelu są zawsze ustrukturyzowane i przewidywalne. Dla architekta systemu, który musi te dane przekazać dalej (do bazy danych, innego API, czy frontendu), to ogromny plus.
Mój krótki poradnik: Jak zacząć z Pydantic AI i lokalnym modelem Ollama
Instalacja i założenia
Zanim zaczniemy, dwa założenia - poradnik opieram na lokalnej Ollama, ale możecie skonfigurować do użycia z Pydentic AI praktycznie dowolny model (instrukcje):
- Ollama musi być zainstalowana i uruchomiona jako usługa na Twoim komputerze. To jest nasz silnik AI, który działa w tle (domyślnie na
http://localhost:11434). - Musisz mieć pobrany model, np.
ollama pull gpt-oss(używam go, bo wspiera tool calling, o moich bojach z małymi modelami i obsługą narzędzi przeczytasz tu: Lokalny agent AI i „Function Calling”: Czy modele poniżej 10B parametrów zawsze zawodzą? Studium przypadku )
Pokazuje w Jupyter, na końcu dam cały plik do pobrania.
Instalujemy pydantic ai

Importujemy potrzebne biblioteki:

import asyncio To standardowa biblioteka Pythona. Jest nam potrzebna, ponieważ Pydantic AI, podobnie jak wiele nowoczesnych bibliotek do obsługi I/O (jak API), działa asynchronicznie. W naszych prostych przykładach użyjemy asyncio.run(), aby uruchomić nasze zapytania do modelu.
from pydantic_ai import Agent To jest serce biblioteki. Agent to nasz główny "pracownik" lub, jeśli wolisz, interfejs. To on będzie zarządzał rozmową, przyjmował nasz prompt, przekazywał go do modelu, a w bardziej złożonych przypadkach także obsługiwał narzędzia (Tools).
from pydantic_ai.models.openai import OpenAIChatModel I tu pierwsza ważna i być może myląca rzecz. Importujemy OpenAIChatModel... mimo że łączymy się z Ollamą. Dlaczego? Ponieważ Pydantic AI używa tej klasy jako uniwersalnego sposobu komunikacji dla modeli, które są kompatybilne ze standardem API OpenAI. A lokalny serwer Ollamy właśnie takie API wystawia. To bardzo sprytne, bo pozwala używać tej samej logiki kodu (OpenAIChatModel) do łączenia się z różnymi dostawcami (OpenAI, Azure, czy właśnie Ollama).
from pydantic_ai.providers.ollama import OllamaProvider To jest nasza "wtyczka" lub "sterownik". Podczas gdy OpenAIChatModel definiuje jak ma wyglądać interakcja (standard API), OllamaProvider mówi gdzie fizycznie wysłać zapytanie. To ta klasa będzie wiedziała, że ma się połączyć z adresem http://localhost:11434 (domyślny adres Ollamy).
Mając te cztery klocki, możemy teraz zbudować nasze połączenie.
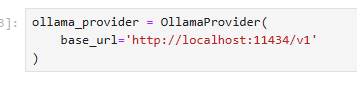
i tworzymy konfiguracje modelu, wykorzystującą powyżej skonfigurowanego dostawcę
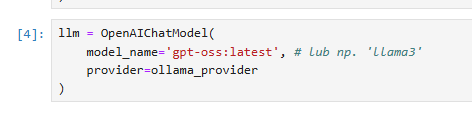
na koniec konfiguracji stawiamy podstawowy obiekt w Pydantic AI, a mianowicie klasę agenta:
agent = Agent(model=llm)Dodajmy proste pytanie do naszego AI:
prompt = "Dlaczego tak lubimy Pythona i SQLa? :)"Wysyłamy pierwsze zapytanie do modelu:
result = await agent.run(prompt)I mamy pierwszą odpowiedź!
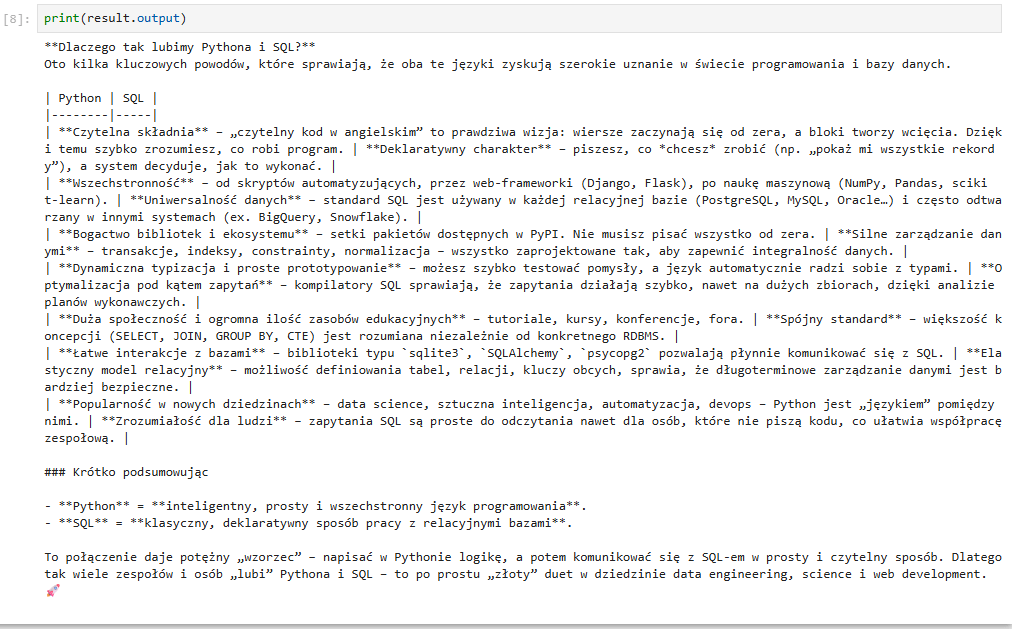
Można by wynik przeformatować do html'a ale jak widzicie mamy to. Podstawa za nami.
Stwórzmy cos praktycznego
Na stornie https://jsonplaceholder.typicode.com/ fałszywe dane do testowania i nauki obchodzenia się z formatem json.
Cały zasób to:
| temat | ilosć rekordów |
|---|---|
| /posts | 100 posts |
| /comments | 500 comments |
| /albums | 100 albums |
| /photos | 5000 photos |
| /todos | 200 todos |
| /users | 10 users |
Dane są powiązane, świetne miejsce do nauki i eksperymentów, ale dla naszego wystarczą podstawowe rzeczy.
Załóżmy, że tworzymy agenta, który będzie pobierał zadania z todo. Damy modelowi funkcje do obsługi, i ustrukturyzujemy przez pydantic formę w jakieś będzie dane zwracał.
Teraz dodajmy system prompt:
sys_prompt = "Twoje zadanie to pobieranie danych o zadaniach do wykonania i zwracanie ich w przyjazdnej formie. na podstawie treści zadania stwóz również hajku"Dodamy model pydantic, zawierający niektóre z danych z API oraz stworzone przez model haiku
class TodoItem(BaseModel):
userId: int
id: int
title: str = Field(description="Tytuł zadania do wykonania")
completed: bool = Field(description="Czy zadanie zostało ukończone")
haiku: str = Field(description="Krótkie haiku po polsku o treści zadania")Do tego przykładu musimy dodać dwa importy:
import requests
import json
i tworzymy drugiego agenta:
agent2 = Agent(
model=llm,
output_type=TodoItem,
system_prompt=sys_prompt,
)czyli w zmiennej output_type dajemy nasz model pydantic a w system_prompt nasz promt systemowy.
A po tym, używając dekoratora tworzymy funkcje od użytku przez model:
@agent2.tool_plain
def get_todo_item(item_id: int) -> str:
"""
Pobiera pojedyncze zadanie (to-do) z publicznego API JSONPlaceholder
na podstawie jego ID. Zwraca dane jako string w formacie JSON.
"""
print(f"--- WYWOŁANIE NARZĘDZIA: get_todo_item(item_id={item_id}) ---")
try:
response = requests.get(f"https://jsonplaceholder.typicode.com/todos/{item_id}")
response.raise_for_status() # Sprawdź, czy nie ma błędu HTTP # Zwracamy tekst (string JSON), AI samo go zinterpretuje
print(f"--- NARZĘDZIE ZWRÓCIŁO: {response.text} ---")
return response.text
except requests.RequestException as e:
print(f"--- BŁĄD NARZĘDZIA: {e} ---")
return json.dumps({"error": str(e)})Użytkownik pyta: user_question = "Pobierz mi pełne dane dla zadania o ID 7 i zwróć je jako obiekt."
i odpalamy:
result_object = await agent2.run(user_question)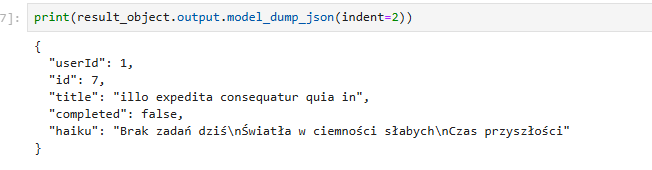
Jak widać odpowiedź to obiekt pydantic. Bardzo wygodna i praktyczna rzecz.
Naprawdę, bardzo wygodny sposób definiowania tools, ale czasem, przy bardziej skomplikowanej strukturze w klasach, można robić to inaczej, bez dekoratora:
agent2 = Agent(
model=llm,
tools=[get_todo_item]
output_type=TodoItem,
system_prompt=sys_prompt,
)W przykładzie używałem @tool_plain - to oznacza, że tool nie potrzebuje do działania kontekstu całej rozmowy z AI bo to agent, który wykonuje konkretne zadanie, ale, gdybyśmy mieli agenta który musi wykonywać szereg czynności, albo asystenta z czatem, wtedy musimy mieć historię tej rozmowy.
W dokumentacji pydantic ai możecie znaleźć też drugi dekorator: @agent.tool. Jaka jest różnica?
Spójrzcie na ten przykład z dokumentacji:
@agent.tool
def get_player_name(ctx: RunContext[str]) -> str:
"""Get the player's name."""
return ctx.depsTo zarządzanie kontekstem, pydantic ma tu elegancki sposób, i może przekazywać kontekst od agenta do narzędzi, bez potrzeby robienia tego ręcznie.
Np Mamy model usera i ten model trafia wprost do tool który pilnuje struktury danych.:
class AppContext(BaseModel):
user_id: int = Field(gt=0) # Walidacja: musi być > 0
user_name: str = Field(min_length=1)
session_id: str preferences: dict = Field(default_factory=dict)
agent = Agent(
model=llm,
deps_type=AppContext
)
@agent.tool
def get_user_data(ctx: RunContext[AppContext]) -> str:
# ctx.deps jest teraz obiektem BaseModel z pełną walidacją
return f"Użytkownik: {ctx.deps.user_name}"I ostatnia rzecz, zarządzanie konwersacją
Agent nie pamięta
Pydantic AI celowo nie przechowuje żadnej historii. Każde wywołanie agent.run() - zaczyna od zera. To bardzo ważne założenie architektoniczne.
Mechanizm działania
Krok 1: Pierwsze zapytanie Gdy pytasz agenta po raz pierwszy, wysyłasz tylko swoją wiadomość. Agent odpowiada i zwraca wynik. W tym wyniku, oprócz samej odpowiedzi, znajduje się pełna transkrypcja wymiany - Twoje pytanie, działania modelu, wywołania narzędzi, wszystko.
Krok 2: Ekstrahowanie historii Po otrzymaniu odpowiedzi możesz wyciągnąć tę transkrypcję metodą .all_messages(). To daje Ci listę wszystkich wiadomości z tej wymiany - jak zapis rozmowy na taśmie.
Krok 3: Dołączanie do kolejnego zapytania Gdy chcesz zadać drugie pytanie, musisz ręcznie podać tę zapisaną historię jako parametr. To tak, jakbyś powiedział agentowi: "Hej, zanim odpowiesz na nowe pytanie, przeczytaj najpierw tę transkrypcję poprzedniej rozmowy".
Krok 4: Model widzi kontekst Teraz agent (właściwie model LLM) dostaje CAŁOŚĆ - starą historię PLUS nowe pytanie. Dzięki temu może odpowiedzieć sensownie, bo "pamięta" (widzi w promptcie) o czym rozmawialiście wcześniej.
Krok 5: Aktualizacja historii Po każdej wymianie znowu wyciągasz .all_messages() - teraz ta lista jest dłuższa, zawiera CAŁĄ konwersację do tej pory. I znowu przy następnym pytaniu musisz ją podać.
Analogia ze spotkaniem
Wyobraź sobie, że agent ma amnezję po każdym spotkaniu. Ale możesz mu przynieść notatki z poprzednich spotkań. On je przeczyta i będzie mógł rozmawiać jakby pamiętał. Ale po spotkaniu znowu wszystko zapomni - więc za każdym razem musisz przynosić coraz grubszy notes z notatkami.
Dlaczego tak to działa?
Bo Ty decydujesz co zrobić z tą historią:
- Możesz ją wyrzucić i zacząć nową rozmowę
- Możesz zapisać do bazy danych
- Możesz usunąć stare fragmenty, żeby nie przekroczyć limitu tokenów
- Możesz mieć 10 różnych rozmów równolegle
Biblioteka daje Ci kontrolę i przezroczystość.
i Przykład:
class ChatContext(BaseModel):
user_name: str
conversation_id: str
preferences: dict = Field(default_factory=dict)
agent = Agent(
model=llm,
deps_type=ChatContext,
system_prompt="Jesteś pomocnym asystentem. Pamiętaj o kontekście rozmowy."
)
# Inicjalizacja
context = ChatContext(
user_name="Anna",
conversation_id="conv-456",
preferences={"language": "pl", "style": "formal"}
)
history = []
# Pierwsza wymiana
result1 = await agent.run(
"Potrzebuję pomocy z Pythonem",
deps=context,
message_history=history
)
history = result1.all_messages()
# Druga wymiana - agent wie o czym rozmawialiśmy
result2 = await agent.run(
"A co z tym frameworkiem, o którym wspomniałeś?",
deps=context,
message_history=history
)
history = result2.all_messages()
I to by było na tyle, mam nadzieję, że niektórym pomogłem w wyborze frameworka, albo wręcz przeciwnie, może to dla was zupełnie bez sensu, jak zawsze proszę o komentarze. Dajcie znać.
0 Komentarzy