
Od lutego 2026 roku Krajowy System e-Faktur stanie się obowiązkowy dla dużych polskich przedsiębiorstw a od Kwietnia dla całej reszty. Rynek oprogramowania księgowego przechodzi gwałtowną transformację. Jednak wbrew powszechnym opiniom, technologie optycznego rozpoznawania znaków i sztucznej inteligencji do przetwarzania dokumentów nie staną się zbędne.
Co KSeF faktycznie zmienia
KSeF eliminuje potrzebę skanowania i rozpoznawania faktur VAT w transakcjach B2B między polskimi kontrahentami. System wymusza ustrukturyzowany format, gdzie dane są już dostępne w formie czytelnej dla maszyn. To rzeczywiście radykalna zmiana dla dziesiątek tysięcy firm, które dotychczas polegały na rozwiązaniach OCR do automatyzacji księgowości.
Problem w tym, że KSeF obejmuje tylko określony podzbiór dokumentów finansowych. Ustawa explicite wyłącza z obowiązku faktury od kontrahentów zagranicznych bez siedziby w Polsce, bilety komunikacyjne, usługi finansowe zwolnione z VAT oraz transakcje w procedurach OSS/IOSS. Dla przeciętnej firmy importującej towary lub usługi, oznacza to że 20-30% dokumentów kosztowych nadal trafia do systemu jako PDF, skan lub papier.
Gdzie OCR zachowuje wartość
Faktury zagraniczne stanowią największą niszę. Każda polska firma współpracująca z dostawcami z Niemiec, Chin, Stanów Zjednoczonych czy Wielkiej Brytanii musi przetwarzać ich dokumenty tradycyjnymi metodami. KSeF nie służy do raportowania transakcji importowych, polska firma otrzymuje PDF lub papierową fakturę i musi samodzielnie wyekstrahować dane do swojego systemu ERP.
Dokumenty podróżne i reprezentacyjne pozostają poza systemem. Bilety lotnicze, przejazdy autostradowe, paragony za delegacje - wszystkie te dokumenty wymagają digitalizacji i ekstrakcji danych. Dla firm z mobilnymi zespołami sprzedaży lub serwisu, to setki dokumentów miesięcznie.
Załączniki do faktur nie trafiają do KSeF. System przyjmuje tylko ustrukturyzowane dane XML. Specyfikacje techniczne, protokoły odbioru, umowy ramowe, kalkulacje kosztorysowe, wszystkie te dokumenty muszą być przechowywane i procesowane osobno. Wiele firm potrzebuje ekstrakcji danych z tych załączników do celów kontrolingowych lub produkcyjnych.
Archiwa historyczne wymagają digitalizacji. Okres przechowywania dokumentów księgowych wynosi minimum 5 lat, a dla środków trwałych często przekracza dekadę. Firmy posiadające wieloletnie archiwa papierowe potrzebują narzędzi do konwersji i integracji z nowoczesnymi systemami.
Koniec ery drogich systemów korporacyjnych
Paradoksalnie, wdrożenie KSeF powinno spowodować spadek zapotrzebowania na złożone, kosztowne rozwiązania OCR klasy enterprise. Jeśli 70-80% faktur przychodzi już w formacie ustrukturyzowanym przez KSeF, inwestycja w system przetwarzający dziesiątki tysięcy dokumentów miesięcznie przestaje mieć sens ekonomiczny.
Firmy potrzebują prostszych narzędzi, które obsłużą pozostałe 20-30% dokumentów. Rozwiązania te muszą być łatwe we wdrożeniu, nie wymagać długich projektów integracyjnych i nie generować wysokich kosztów licencyjnych per dokument czy miesięcznych. Rynek przesuwa się w stronę modułowych, specjalizowanych systemów zamiast monolitycznych platform.
Dla małych i średnich firm otworzyła się przestrzeń na rozwiązania on-premise lub hybrid, które pozwalają zachować kontrolę nad danymi i uniknąć vendor lock-in. Lokalne przetwarzanie z wykorzystaniem open-source'owych modeli AI staje się realną alternatywą dla chmurowych API rozliczanych za tokeny choć ich nie eliminuje, w zależności od posiadanej infrastruktury.
Moje rozwiązanie
W ciągu ostatnich tygodni zakończyłem pracę testami skanowania i ocr. Jestem w trakcie tworzenia rozwiązania który adresuje właśnie te potrzeby. Zamiast tworzyć kolejną platformę SaaS, skupiłem się na architekturze którą firmy z moją pomocą mogą wdrożyć wewnętrznie i zintegrować z istniejącymi procesami KSeF.
System wykorzystuje system parsowania dokumentów oparty na uczeniu maszynowym oraz lokalne (lub chmurowe) modele językowe do ekstrakcji danych. Całość może działa bez wysyłania dokumentów do zewnętrznych API, co rozwiązuje problemy compliance dla branż regulowanych.
Wkrótce pokażę szczegóły techniczne i wyniki testów wydajnościowych. Zbudowałem to inaczej niż typowe rozwiązania rynkowe, stawiając na prostotę wdrożenia i niskie koszty operacyjne zamiast na długą listę funkcji które większość klientów nigdy nie wykorzysta.
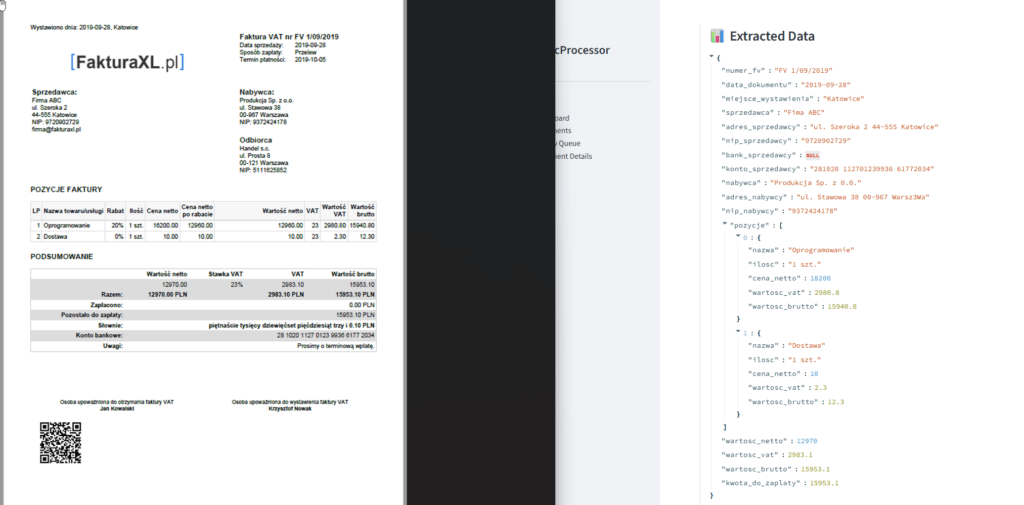
Przykład zczytania faktury z popularnego polskiego programu księgowego:
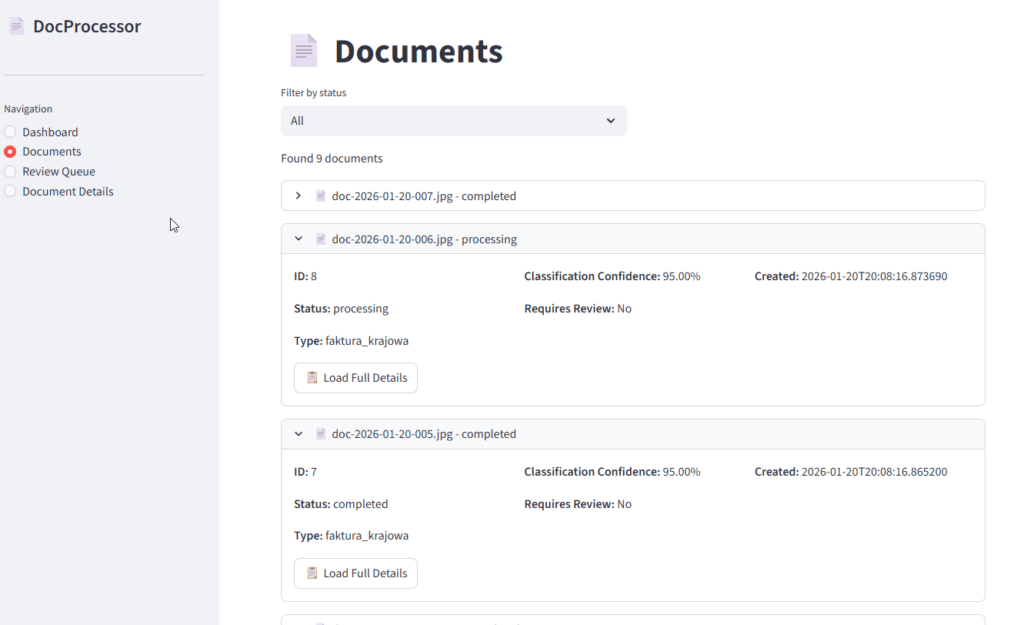
Kolejka dokumentów:
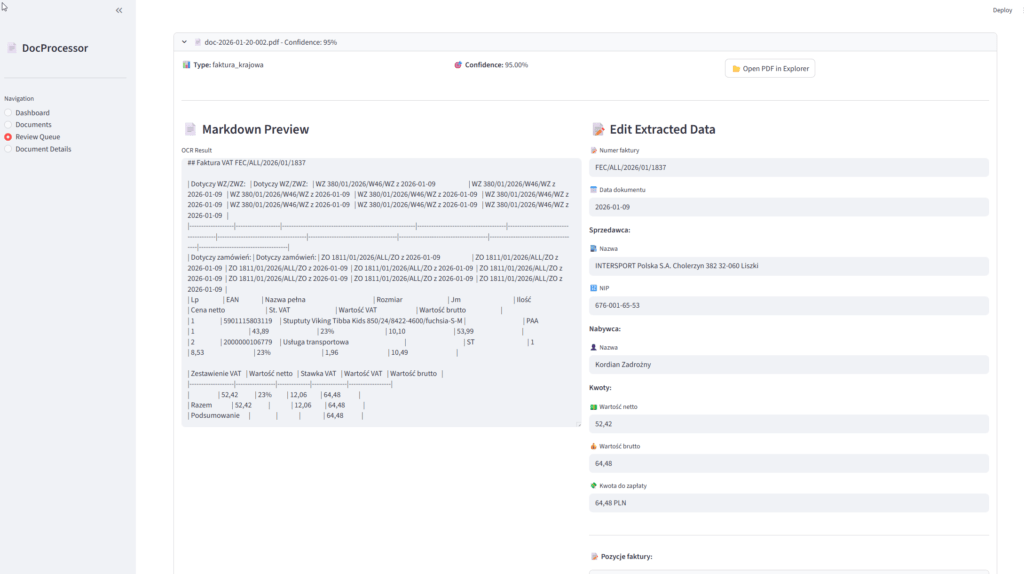
Weryfikacja z podglądem oryginału w markdown:
Chętnie takie rozwiązanie wdrożę po godzinach w twojej organizacji (jestem freelancerem po 17 i w weekendy).
Nie mam działalności, korzystam z faktur wystawiany przez useme

0 Komentarzy